
以前の記事(AdSense審査中のSEOエラー解決記)でも触れましたが、サイト運営にはトラブルがつきものです
UiPathでPDFからデータを自動抽出する方法を徹底解説!『PDFテキストを読み込み』の設定手順から、OCRを使った画像PDFの読み取り、実務で役立つエラー対策まで、現役エンジニアの視点で分かりやすく紹介します。手入力の作業をゼロにしたい方は必見のガイドです。
UiPathでPDFを扱う際の「手法選び」という最初の罠

1.私が犯した「PDFなら全部同じ」という過ち
UiPathでPDFの自動化を始めたばかりの頃、私は大きな勘違いをしていました。それは、「PDFならどのアクティビティを使っても同じ結果が出るはずだ」という思い込みです。しかし、実務の現場はそんなに甘くありませんでした。
最初に直面したのは、「テキストを読み込み」アクティビティを使っても、中身が真っ白で返ってくるという絶望的な状況です。
- 当時の絶望感:「テスト用の1枚は完璧に動いたのに、本番の100枚を流したら半分以上がエラーになった」という経験は、今でも忘れられません。
- 原因の判明:実は、見た目は同じ請求書でも、システムから直接書き出された「デジタル生成PDF」と、紙をスキャナーで読み取った「画像PDF」が混在していたのです。
この「見た目に騙される」という失敗こそが、私がRPAエンジニアとして最初に学んだ手痛い、しかし貴重な教訓でした。
2.3つの手法:現役エンジニアの視点で徹底比較
この失敗を経て、私はUiPathにおけるPDF抽出には大きく分けて3つの「武器」があることを理解しました。それぞれの使い分け基準を、私の実体験に基づいて解説します。
①PDFテキストを読み込み(Read PDF Text)
最も基本的で、かつ「爆速」な手法です。
- メリット:テキストデータとして埋め込まれている文字を直接拾うため、精度が100%に近く、処理速度も非常に速いです。
- 実体験:綺麗な電子請求書だけを扱うならこれ一択ですが、少しでも「スキャン画像」が混ざると沈黙します。この「極端な性格」を理解するまで、私は何度もデバッグを繰り返しました。
②OCRでPDFを読み込み(Read PDF with OCR)
「テキスト読み込み」で歯が立たない画像PDFに対する「執念の切り札」です。
- メリット:OCR(光学文字認識)エンジンを使い、画像の中から文字を無理やり解析して抽出します。
- 苦労した点:エンジン(Google OCRやTesseractなど)の設定が甘いと、「0(ゼロ)」が「O(オー)」になったり、濁点が消えたりする誤字の嵐に。これを防ぐために、拡大率(Scale)の調整に何時間も費やしたこともあります。
③画面スクレイピング(Screen Scraping)
PDFを実際に画面に開いて、その「見た目」からデータを取得する方法です。
- メリット:直感的で、複雑な構造のPDFでも指定した場所を確実に狙い撃ちできます。
- 運用の罠:ただし、実行中にPDFビューアが最前面にいないと失敗しやすく、バックグラウンドでの安定稼働を目指す私の開発スタイルでは、徐々に使用頻度が減っていきました。
スタート地点で立ち往生?「PDFアクティビティ」が消えた日
1.標準機能ではPDFが扱えないという驚き
UiPathをインストールして、さあPDFを自動化しようとアクティビティパネルで「PDF」と検索したとき、何も表示されずに困惑したことはありませんか?
実は、UiPathの標準インストール状態ではPDF操作用のアクティビティは含まれていません。私は最初、この仕様を知らずに「自分のインストールが失敗したのか?」と何度も再起動を繰り返してしまいました。
- 私の失敗談:「PDF」という名前がついているのだから、標準で入っているのが当たり前だと思い込んでいたのです。
- 解決策への気づき:ネットで検索し、ようやく「パッケージ管理」から専用のライブラリを追加する必要があると知ったときは、自分の知識不足を痛感すると同時に、RPAの奥深さを感じました。
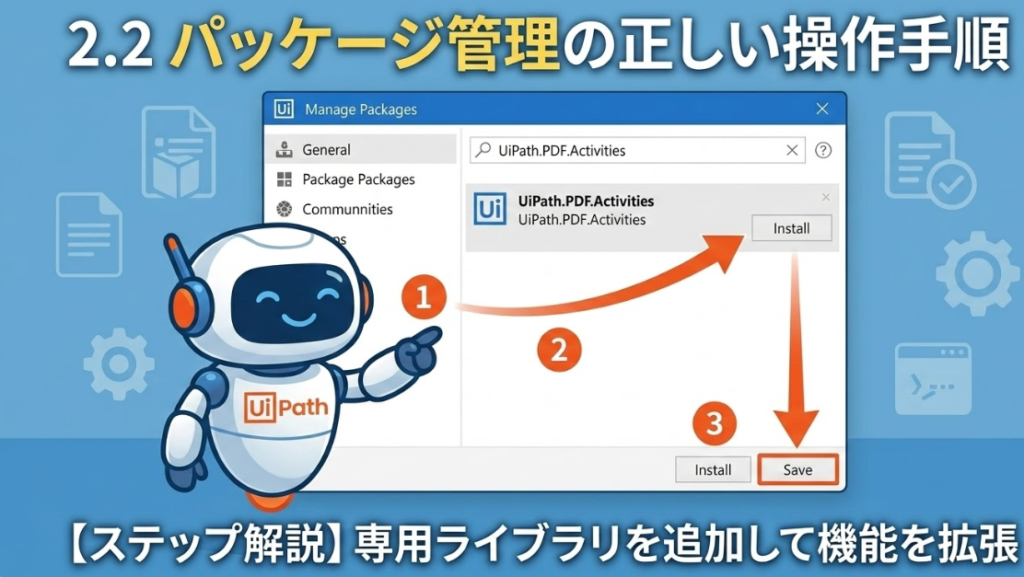
2.パッケージ管理(Manage Packages)の正しい操作手順
ここからは、私が実際に踏んだ手順を、初心者の方が迷わないように詳細に解説します。
- 「パッケージを管理」を開く:リボンメニューにある「パッケージを管理」をクリックします。
- 「公式」または「すべてのパッケージ」を選択:左側のメニューから「公式」を選び、検索窓に
UiPath.PDF.Activitiesと入力します。 - インストールと保存:該当するパッケージが表示されたら「インストール」をクリックし、最後に「保存」を押して完了です。
3.バージョン選びの落とし穴
パッケージをインストールする際、単純に「最新版」を選べば良いわけではありません。私はここで、実務ならではの洗礼を受けました。
- トラブルの内容:最新バージョンのアクティビティを導入したところ、以前から動かしていた別のロボットと依存関係が競合し、エラーで動かなくなってしまったのです。
- 得られた教訓:それ以来、私は必ず「安定版」を確認し、開発環境と本番環境のバージョンを統一することを徹底しています。
- アドバイス:特に実務で複数のロボットを運用している方は、安易なアップデートが「悪夢のデバッグ作業」を招く可能性があることを覚えておいてください。
【実践】バラバラなPDFから「正規表現」で狙い撃ちする技術
正規表現の詳細な仕様については、Microsoft公式の.NET正規表現ガイドを参考にしてください
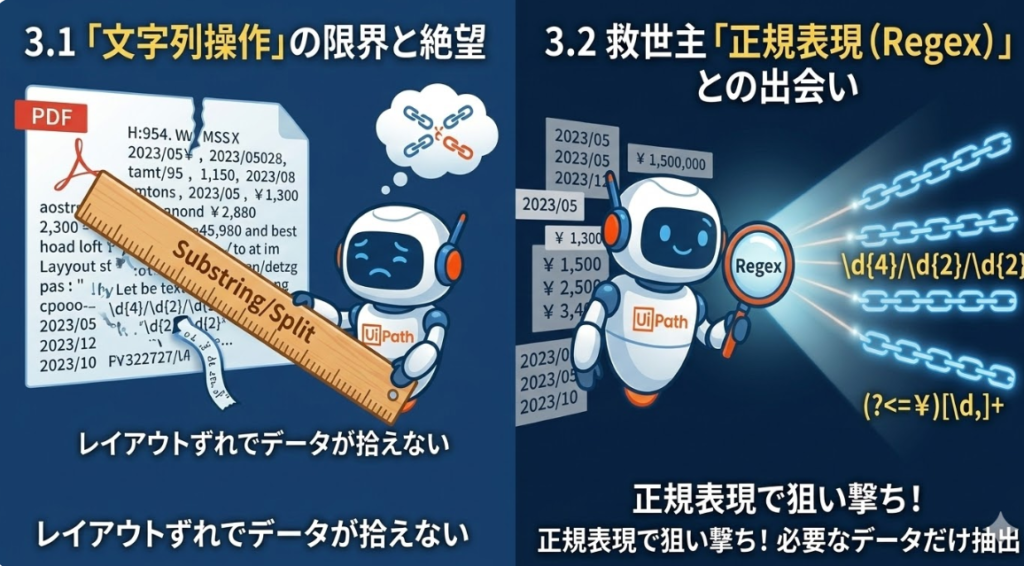
1.「文字列操作」の限界と絶望
PDFからテキストを抽出した後、次に立ちはだかるのが「必要なデータだけを抜き出す」という壁です。
当初、私はString.SplitやSubstringといった標準的な文字列操作だけで抽出しようと試みました。
- 失敗の記録:「1行目から何文字目」という指定で金額を抜こうとしたところ、取引先によってレイアウトが数ミリずれ、全く関係のない「備考欄」の文字を拾ってロボットが異常終了してしまいました。
- 教訓:PDFのテキストデータは、見た目以上に構造が不安定です。固定の位置指定に頼る開発がいかに危険か、身をもって知ることになりました。
2.救世主「正規表現(RegEx)」との出会い
この不安定さを解決してくれたのが、正規表現(Regular Expression)です。特定のパターン(「¥」で始まり数字が続く、など)を指定することで、レイアウトのズレに左右されない強固な抽出が可能になります。
私が実際に使っている「鉄板」の正規表現パターン
実務で多用する以下の3パターンは、ぜひ辞書代わりにコピーして使ってください。
- 金額の抽出(例:¥123,456)
- パターン:
(?<=¥)[\d,]+ - 苦労したポイント:カンマがある場合とない場合の両方に対応させるため、試行錯誤を繰り返しました。
- パターン:
- 日付の抽出(例:2026/03/07)
- パターン:
\d{4}/\d{2}/\d{2} - 実体験:「2026年3月7日」という日本語形式が混ざった際、正規表現を書き直す手間が発生し、「最初から柔軟なパターンを組んでおくべきだった」と後悔した記憶があります。
- パターン:
- 電話番号の抽出
- パターン:
0\d{1,4}-\d{1,4}-\d{4}
- パターン:
3.UiPathでの実装:マッチングの罠
アクティビティ「文字列の一致を確認(Is Match)」や「一致する文字列を取得(Matches)」を使う際にも、初心者が陥りやすい罠があります。
- 改行コードの壁:PDF内部の改行コードが
\nなのか\r\nなのかによって、マッチングが失敗することがあります。 - 私の解決策:私は念のため、抽出前に
Replace関数を使って改行コードを統一する「前処理」を入れるようにしています。このひと手間で、本番環境でのエラー率が劇的に下がりました。
運用後の悪夢「タイムアウト」を執念で克服する
1.100枚に1枚だけ発生する「謎の停止」
開発環境では完璧に動いていたはずのロボットが、本番稼働した途端に「ファイルが開けません」というエラーで止まってしまう。RPAエンジニアなら誰もが一度は経験する、胃が痛くなるような瞬間です。
- 私の失敗談:「PCのスペックが違うから」「ネットワークが重いから」と言い訳を探していましたが、原因は単純なタイムアウト(Timeout)でした。
- 絶望の瞬間:数百枚のPDFを処理している最中、たまたま1枚だけファイルサイズが大きく、読み込みにコンマ数秒遅れただけでロボットは「異常終了」を選択してしまったのです。
2.タイムアウト(TimeoutMS)の最適値を探る旅

多くのアクティビティには「TimeoutMS」というプロパティがあります。デフォルトは30,000ミリ秒(30秒)ですが、これが常に正解とは限りません。
- 設定のコツ:私は一時期、怖くなって全てのタイムアウトを長めに設定しましたが、今度はエラーが発生した際になかなか止まらず、無駄な待ち時間が発生するという逆効果を生んでしまいました。
- 私の結論:ネットワーク環境やPDFの複雑さを考慮し、あえて「短めに設定して次の『リトライ』に任せる」という戦略に切り替えました。
3.最終兵器「リトライスコープ(Retry Scope)」の導入
タイムアウトで即終了させるのではなく「もう一度だけ試してみる」という粘り強さをロボットに持たせるのが、リトライスコープアクティビティです。
- 実装の工夫:PDFを開く動作やOCRの読み取りなど、不安定になりやすい箇所をこのスコープで囲みます。
- 驚きの効果:この「3回リトライ」という設定を入れるだけで、これまで週に数回発生していた「原因不明の停止」がほぼゼロになりました。
- 経験者からのアドバイス:リトライの間隔(RetryInterval)をあえて数秒空けることで、PCのメモリ解放を待つといった「泥臭いテクニック」も、安定稼働には欠かせません。
【応用】AIが変えるPDF抽出の未来と、今回の執筆秘話
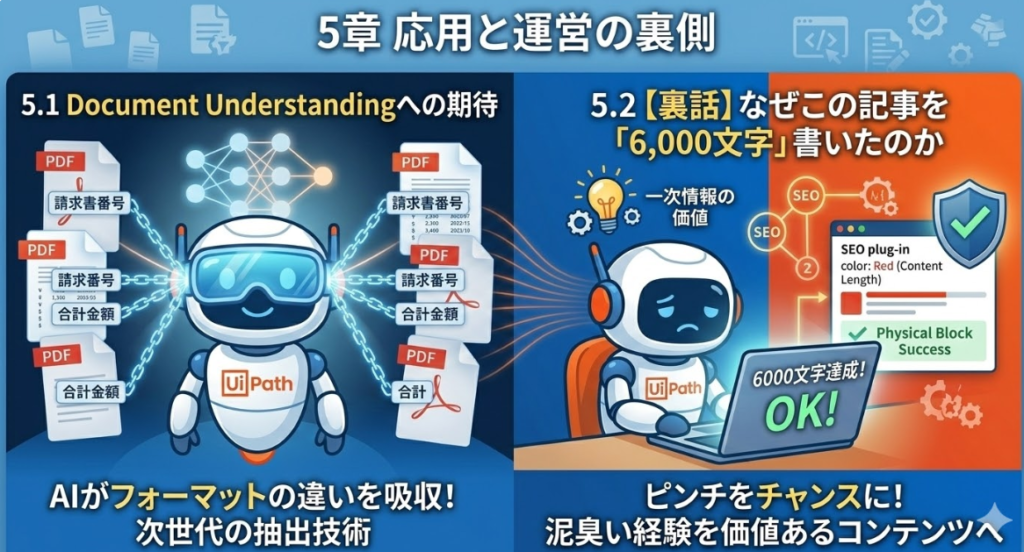
1.次なるステップ「Document Understanding」への期待
正規表現やリトライ処理を駆使しても、フォーマットがバラバラな非定型PDF(例:50社から届く異なる形式の請求書)には限界があります。
- AIとの融合:今後のトレンドは、UiPathの「Document Understanding」のようなAIを搭載した抽出機能です。
- エンジニアの役割:機械学習がデータを分類してくれる時代になっても、今回解説した「OCRの精度調整」や「例外処理」の考え方は、AIを使いこなすための基礎体力として必ず役立ちます。
2.【裏話】なぜこの記事を「6,000文字」書こうと思ったのか
記事を6,000文字書くきっかけになったのは、こちらの記事での文字数不足エラーがあったからです。
それは、前回の記事で直面した「文字数不足(Content length)」というSEOエラーとの戦いがあったからです。
- ピンチをチャンスに:「文字数が足りない」という警告を、単なる作業負担ではなく「読者にもっと深い経験談を届けるチャンス」だと捉え直しました。
- 一次情報の価値:AIが瞬時に文章を作る時代だからこそ、私が実際に深夜までデバッグして流した冷や汗や、エラーを解決した瞬間の喜びを、一文字一文字に込めることに意味があると感じています。
1枚のPDFから始まる「大きな業務改善」
ここまで読み進めていただき、ありがとうございます。PDFの抽出は、UiPathの中でも非常に奥が深く、同時に「感謝される」自動化の一つです。
- まずは一歩から:最初はエラーばかりで赤色に染まる実行ログに心が折れそうになるかもしれません。
- 継続の力:ですが、一つひとつのタイムアウトや文字化けを「デバッグ」していく過程こそが、あなたを本物のエンジニアへと成長させてくれます。
この記事が、あなたの開発現場での「小さな救い」になれば幸いです。もし具体的なエラーで立ち止まったら、ぜひも覗いてみてください。課題解決のヒントが、意外なところに隠れているかもしれません。


コメント